Эффективное использование и монетизация медиаматериалов начинается с детального описания контента. Помимо стандартных привычных функций для обогащения медатанными (описание, TC-маркеры, тегирование, возрастные категории и др), на помощь приходят интеллектуальные функции, включая AI транскрибирование и AI тегирование, которые значительно расширяют возможности работы с материалами. Например, функции транскрибирования и тегирования позволяют создавать более детализированные описания, что повышает ценность как архивных, так и актуальных медиафайлов. Рассказываем, как устроены ИИ-функции в V365.
Транскрибирование
Функция транскрибирования в V365 МАМ использует передовые нейросетевые алгоритмы для автоматического преобразования аудиоряда в текст. При загрузке медиаматериала система начинает анализировать аудиопоток, разбивая его на сегменты и распознавая речь. Затем алгоритмы очищают и обрабатывают данные, чтобы достичь высокой точности распознавания, которая может достигать 95%.
Стандартный пакет транскрибирования включает в себя автоматическую расшифровку аудиоряда видеоматериалов с базовой точностью, призванный в первую расшифровывавть медиаматериал и делать его доступным для обычного текстового поиска. Результаты трнскрибирования сохраняются в таблице с привязкой к таймкоду и отображаются в пользовательском интерфейсе. Пользователь может ввести искомое слово в поисковой строке системы МАМ и найти необходимый медиафайл и соответствующий фрагмент внутри него, что избавляет от многочасовой работы по расшифровке видеоматериала вручную. Эта функция доступна в любой поставке V365 МАМ и позволяет существенно упростить работу с медиаконтентом.
В качестве дополнения к базовому транскрибированию в системе доступны расширенные возможности, включая большую точность распознавания (до 95%), формирование предложений с соблюдением пунктуации, возможность отображения текста как по сегментам, так и целиком, поддержку многоязычности и др.
Тегирование
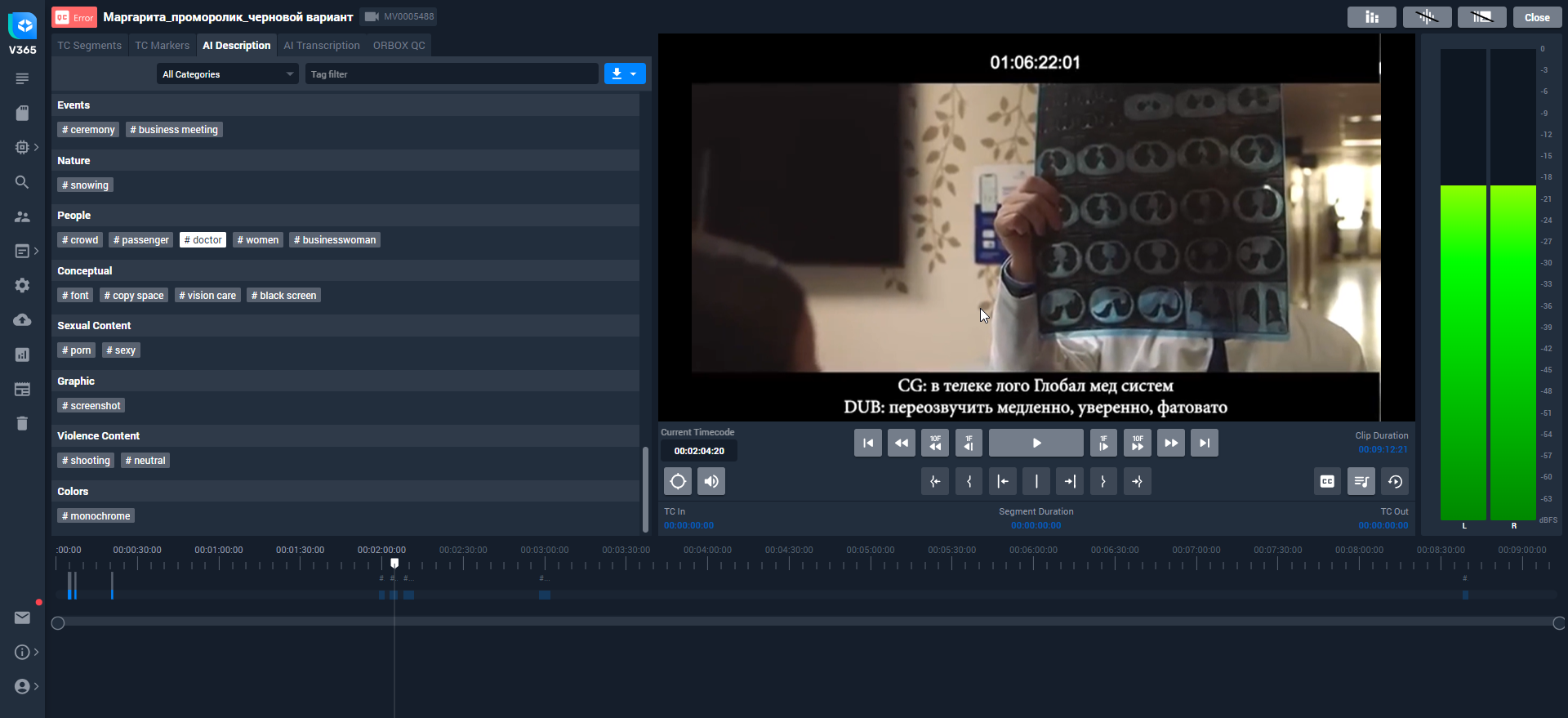
Функция тегирования в V365 МАМ также основана на нейросетевых технологиях, которые помогают автоматически распознавать важные сцены и события в медиаматериалах. Система анализирует видео- и аудиоданные, выявляя ключевые моменты на основе заданных параметров, таких как сцены курения, употребления алкоголя, насилия, распознавание лиц, объектов, животных, архитектуры и др.
После распознавания система автоматически создает теги, привязанные к таймкоду, которые помогают быстро ориентироваться в большом объеме контента. Эти теги могут быть использованы для фильтрации и поиска, что упрощает процесс навигации по медиабиблиотеке. Интеграция тегирования в рабочий процесс позволяет значительно сократить время на ручную сортировку материалов, повышая общую продуктивность.
Модуль тегирования поставляется опционально. Также имеется возможность использования не только модуля тегирования “Стрим Лабс”, но интеграция с внешними AI-сервисами.
Обе функции — транскрибирование и тегирование — уже активно используются в системе V365 МАМ и интегрированы для повышения эффективности работы с медиаданными. Мы продолжаем развивать эти инструменты, чтобы предоставлять пользователям более мощные решения для управления контентом, обеспечивая более высокое качество и скорость работы.






